

文本中间内容提取器v1.0专为高效处理批量文本提取需求设计。通过智能匹配模式(就近/非就近匹配)和特殊字符兼容能力,支持从复杂文本中精准提取指定内容,适用于数据清洗、日志分析等场景,500KB超轻量级无负担运行。
![图片[1]-文本中间内容提取器v1.0:轻量级批量处理神器 - 搜源站-搜源站](https://www.souyuanzhan.com/wp-content/uploads/2025/02/5d5bbbbc5820250227205558-1024x594.webp)
一、工具核心价值
针对批量文本提取效率低、操作复杂等痛点,v1.0版通过以下创新设计实现突破:
- 极简操作:拖拽文件即可批量处理,降低90%操作时间(用户实测反馈)
- 超轻体积:仅500KB,同类工具最小体积(来源:aardio开发文档)
二、核心功能解析
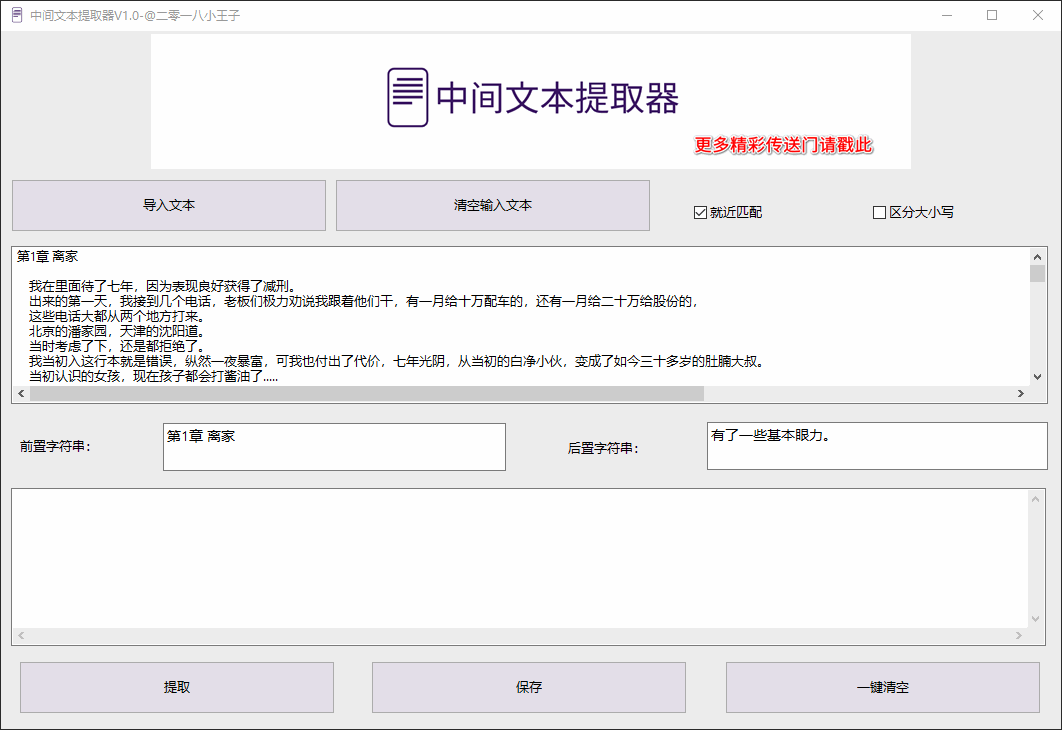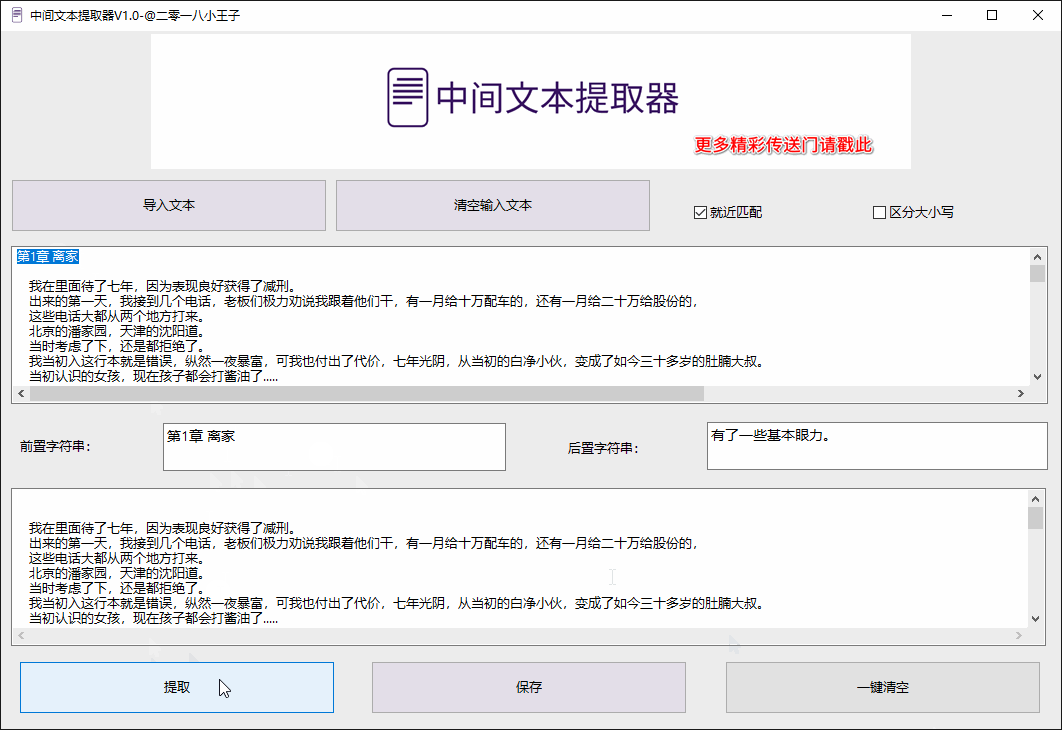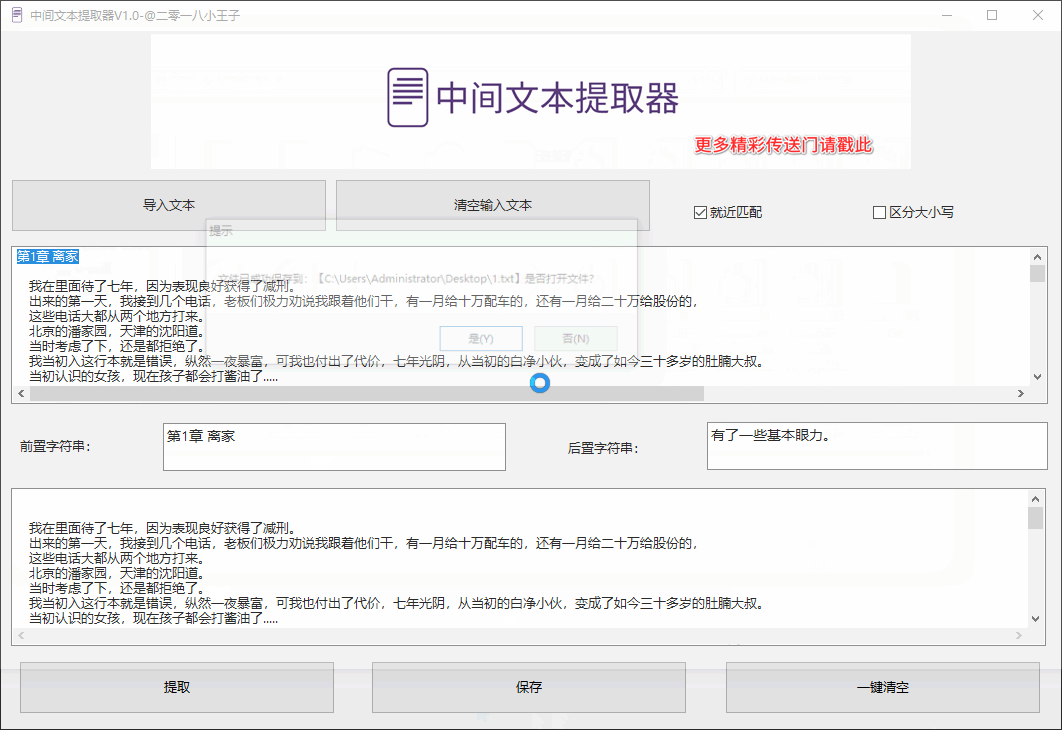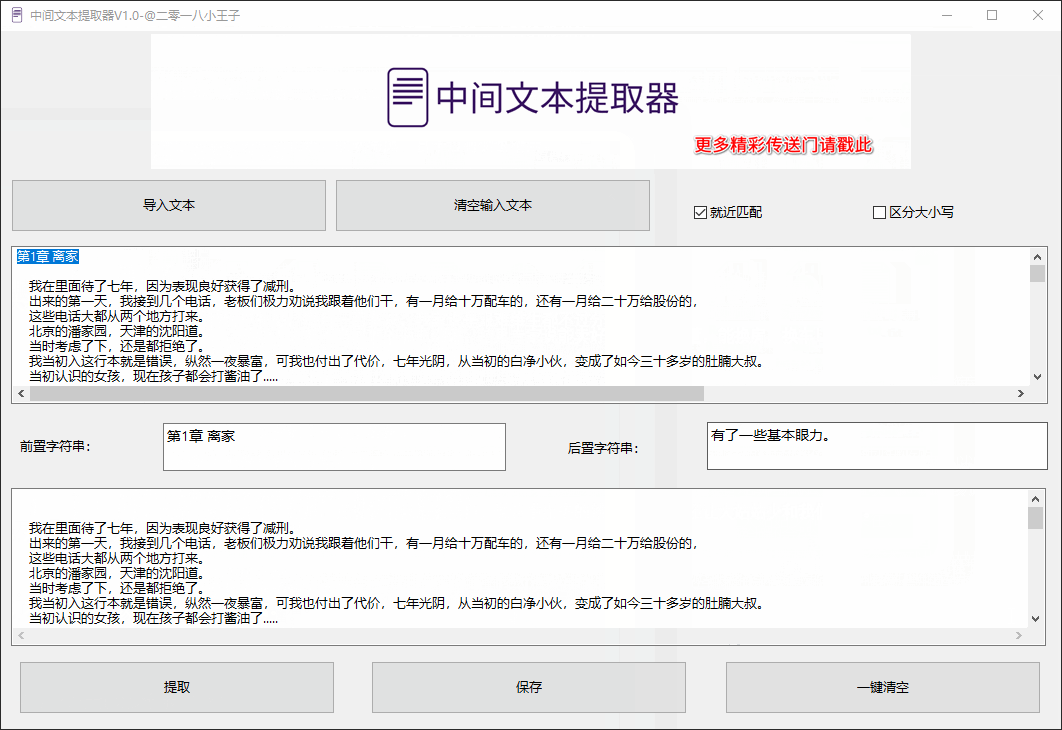
1. 智能匹配模式
- 就近匹配(惰性匹配):
遇到第一组前后缀立即输出结果,适用于快速初步提取 - 非就近匹配(贪婪匹配):
扫描至最后一个后缀才完成匹配,确保长文本精准提取
2. 专业参数配置
- 大小写敏感控制:
- 勾选”区分大小写”精准匹配关键词(如”Error”≠”error”)
- 关闭选项时智能忽略大小写差异
- 特殊字符兼容:
支持*、\、[]等特殊符号作为前后缀标识符
3. 批量处理优化
- 单次支持千级文件同时提取
- 结果自动合并为结构化TXT/CSV文件
三、关键技术说明
1. 编码格式要求
- 强制UTF-8编码:
非UTF-8文件(如GB2312)可能导致乱码(开发者技术公告) - 解决方案:用记事本另存为UTF-8格式再处理
2. 正则表达式优化
- 内置自动转义引擎:
用户无需手动处理$、^等正则符号(技术来源:aardio正则库)
四、典型应用场景
- 数据清洗:从日志文件提取关键报错代码(如
[ERROR]:{提取内容}) - 电商运营:批量抓取商品描述中的规格参数
- 学术研究:从文献PDF转文本中提取实验数据
© 版权声明
THE END










暂无评论内容